ARTICLES
Craq - Terrace and Freedman
By adam
questions
- what is the interface provided
- simple k,v store
what are the guarantees discussed
- strong and eventual consistency
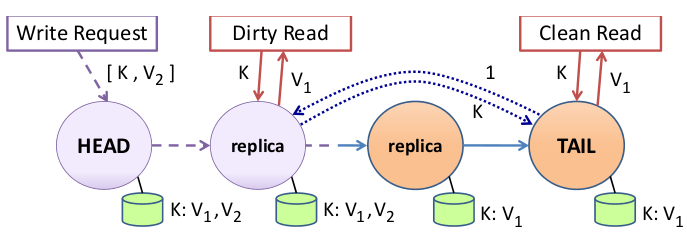
chain replication
- where are requests handled?
- write at head
- read at tail
- what is the dotted line going back from tail to head
- reply to the “write” client - committed
- why is this cheaper than other topologies
- because of pipelining of the writes down the chain
- what consistency does CR achieve?
- strong consistency
- at what cost?
- read throughpout
apportioned queries
- explain dirty and clean
- after writing before receiving acknowledgement it is dirty
- what happens to a node on a dirty rad
- tail asks the tail’s last committed version number, then it returns that version of the object
- explains why this is still satisfying strong consistency
- reads are serialized wrt tail
- i.e. only returning a read that has already been committed
- how does node know if clean or dirty without a flag
- if it has two versions of the data it is dirty
- deletes old version when received an acknowledgement
- why not just return the older version and return the newer version after the
acknowledgement?
- if you do, then nodes away from the tail receive acknowledgement after the write has already been committed by the tail, thus not sending the most recent data
workload
- read heavy workload - how is craq better than cr
- for clean reads, increase by factor \(C-1\), since all non-tail nodes participate in the read
- write heavy workload
- the tail still experiences heavy workload, but the response is just its commit version number, lighter-weight than full reads
- eventual consistency with max-bounded inconsistency
- limit dirty reads bounded by local time or version number
scaling out
- chain identifier
- determine which chain contains the object
- key identifier
- a unique naming per chain
- configuration specifications
- num_dc’s, chain_size
- consistency hashing to figure out which dc stores the chain
- chain_size, dc1, dc2, …, dcn
- all dc’s use the same chain size head in dc1 tail dcn
- num_dc’s, chain_size
- distribution of chains not very well explained
zookeeper
- used for node memebership
- zookeeper not optimized to run in multi-datacenter environment
- zookeeper hiearchy
multichain operations
- locks in all the rows at involved heads
multicast
- pass writes in multicast mode
- propagate metadata message down the chain to ensure that all replicas have
received the multicast
- if not received, then commit is hung at the predecessor while node is updated
- tail may acknowledgement in multicast
- reduce time for commit
- no ordering or reliability guaranteee in multicast acks
- if a node doesn’t receive an ack it will enter clean state on next read op??
zookeeper implementation
- client creates ephemeral node /nodes/dc_name/node_id
- content: ip address:port
- nodes can query /nodes/dc_name for membership list - use watch
- node receives request to create a new chain
/chains/chain_id
- the chain’s placement strategy
- participating nodes will query for this metadata information and set watch
- nodes in chain do not register their membership for each chain they belong
together
- chain metadata contains all the nodes
- why?
- number of chains > 10x number of nodes
- chain dynamism > than nodes leaving and entering the system
- for scalability
- each node can track only a subset of datacenter nodes
- partition the /nodes/dc_name according to node_id prefixes
- zookeeper api is asynchronous
- wrapper functions to twait (tame-style) wait
chain node functionality
- one-hop DHT using identifiers
- node’s chain predecessor and successor are defined as its predecessor and successor in the DHT ring
- https://en.wikipedia.org/wiki/Chord%5F(peer-to-peer)
handling membership changes
- backpropagation
- if new head gets added to the chain
- old head needs to propagate its state backwards
- if new head gets added to the chain
- needs to be robust to subsequent failures, i.e. head may fail, responsability of next node in line to backpropagate
- when new node joins the system
- new node receives prop messages from predecessor and backprop from successor
- set reconciliation algorithm
- enusre that only objects needed are propagated
- both clean and dirty versions need to be sent
- to respond to future acks
- normal writes only the latest version is sent
- recovery from failure or adding new node, full state is sent
example for new node A
- N -> A
- N prop all objects in C to A
- if A was there before use set reconciliation
- A -> N
- N back-prop all objects in C to A (for which N is not head?)
- tail is kind of weird (fixed size system)
- A takes over as the tail of C if N was tail
- N becomes tail if N -> tail
- A is new head if N was head and C<A<N
example of deleting A
- N -> A -> B
- N prop to B
- because A could have been propagating something to B
- N prop to B
- B -> A -> N
- N backprop to B
- because A could have been sending an ack or be in the middle of backprop
- N head if A was head
- if N tail, then relinquishes to new tail and props to it
- N backprop to B
evaluation
- for 3 nodes what is the increase in read throughput
- 3x
- write throughput vs test-and-set throughput
- write slightly decreases with chain length
- T&S decreases with chain length, because of latency of single operation increases
- how do write affect reads?
- goes from 3x to 2x
- tail saturation point for combined read and version request is still higher than read requests alone
- goes from 3x to 2x
- as write increases
- number of clean requests drop to 1/4 of its original
- tail cannot maintain 1/3 of total throughput, also handling version queries
- number of dirty requests approaches 2/3 of original clean requests
- dirty requests are slower, dirty requests flattens out at 42.3%
- total read rate is 25.4 + 42.3 = 67.7 of read throughput during high write