ARTICLES
DynamoDB
By adam
Highlights
- kv store
- data partitioning and replication by consistent hashing
- consistency facilitated by object versioning
- consistency among replicas during update by quorum
- decentralized replica synchronization
- gossip based distributed failure detection and membership
Background
- Authors confuse ‘C’ in ACID with ‘C’ in CAP
2.3
- optimistic replication - conflict resolution when you need item
- allow writes/updates - “always writable”
- pushes complex conflict resolution on the reader
- at data store means “last write wins”
- too simple, allow client to do the conflict resolution
Related work
- “always writable” requirement
- trusted nodes
- simple k-v
- latency ~ 100-200ms
- zero-hop DHT, each node can route request to appropriate node
System architecture
- components:
- data persistence component
- load balancing
- membership
- failure detection
- failure recovery
- replica synchronization
- overload handling
- state transfer
- concurrency
- job scheduling
- request marshalling
- request routing
- system monitoring
- system alarming
- configuration management
- cover:
- partitioning
- replication
- versioning
- membership
- failure handling
- scaling
system interface
- api get and put
- get(key)
- locates object replicas
- returns with conflicting versions
- returns with a context
- put(key, context, object)
- determines which replica
- context : metadata such as version
- key and object are opaque array of bytes
- use MD5 hash to generate a 128-bit id
partitioning
- consistent hashing
- each node assigned a random position in the ring
- each data item hashed to ring and served by first node larger position
- each node serves data between it and its predecessor
- each node actually mapped to multiple points in the ring (tokens)
- virtual node advantages
- if node goes down, load gets handled more evenly by other nodes
replication
- data item is replicated at \(N\) hosts
- each key assigned to a coordinator node
- coordinator is in charge of replication of the data items that fall in its range
- coordinator replicates key at N-1 clockwise successor nodes in the ring
- each node is responsible for between it and its \(N\) th predecessor
- preference list is the list of nodes responsible for a key
- every node in the system can determine which nodes for a key
- the pref list skips positions in the ring to ensure that it contains only distinct physical nodes
data versioning
- eventual consistency, data propagates asynchronously
- guarantees that writes cannot be forgotten or rejected
- each modificaiton is a new and immutable version of the data
- version branching can happen in the presence of failures resulting in conflicting versions, client must perform reconciliation
- vector clocks used to capture causality
- (node, counter)
- if the counters of an object are less-than-or-equal to all the nodes in a second clock, the first is an ancestor
- on update, client must specify which version is being updated
- pass the context from earlier read
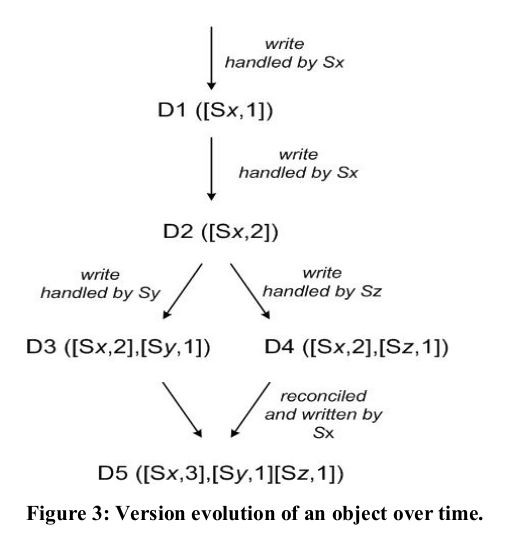
- timestamp is used to truncate the clock which may be growing
get and put operations
- route request through LB
- use partition aware client library that routes to coordinator
- requests received through a LB routed to any random node in ring
- node will forward to the first among top \(N\) in preference list
- quorum protocol \(R+W > N\)
- put(), coordinator generates vector clock for new version
- sends to \(N\) highest-ranked reachable nodes
- if \(W-1\) nodes respond then the write is considered successful
- get(), coordinator requests all existing versions of data forward for that key, wiates for \(R\) responses before returning value to client
handling failure
-
hinted handoff
- loose quorum membership “sloppy quorum” : first \(N\) healthy nodes from preference list

-
anti-entropy, replica synchronization protocol
-
merkle tree
- each branch can be checked independently without checking entire tree
- each node maintains a separate merkle tree for each key range
- two nodes exchange the root of the merkle tree for key range
membership and failure detection
- gossip based protocol propagates membership changes
- maintains an eventually consistent view of membership
- each node contacts a peer chosen at random every second
- two nodes reconcile their persisteted membership change histories
- nodes choose set of tokens (virtual nodes in the consistent hash space) and maps nodes to their respective token sets
- mapping persisted on disk, contains local node and token set
- mappings reconciled via gossip
seeds
- special nodes known to all nodes
- seeds obtained through static config or config service
- all nodes must reconcile at seeds, logical partitions unlikely
failure detection
- local notion of failure, if node A can’t communicate with B, then uses alternate nodes
- decentralized failure detection use simple gossip-style protocol
adding and removing storage nodes
- transfer keys to new node
- reallocation of keys upon removal
Uneven partitioning
- assigning to a data range between virtual nodes skews the distribution of data among the virtual nodes
- instead break the (hashed) data into Q ranges (fixed size)
- assign to each node \(\sum Q/S\) where \(S\) is the number of nodes
- membership mapping then will look like
| Q | Node |
|---|---|
| 1 | a,c,d |
| 2 | a,f,k |
| 3 | a,p,m |
- when you delete node a, replacements are added from the other remaining nodes, since a was taking care of a fixed number of Q sections, then the redistribution among other nodes will also be of fixed size
Conclusions
- not very useful