ARTICLES
Facebook - memcached
By adam
Requirements
- real-time
- aggregate dispersed data
- access hot set
- scale
- refs [1,2,5,6,12,14,34,36]
Front-end cluster
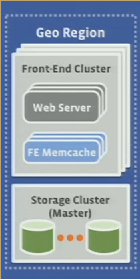
- read heavy workload (100:1 R/W)
- wide fanout
- handle failures
- 10 Mops/s
Q: what is a wide fanout
Multiple FE clusters
- single geo region
- control data replication
- data consistency
- 100 Mops/s
Multiple regions
- muliple geo regions
- storage replication
- data consistency
- 1 Bops/s
Pre-memcached
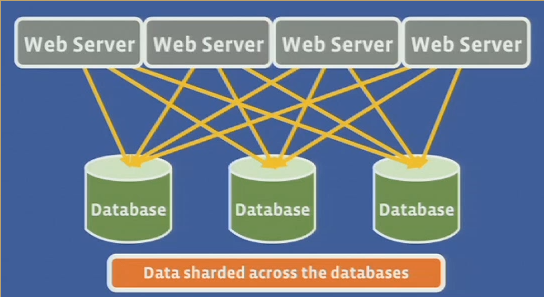
High fanout
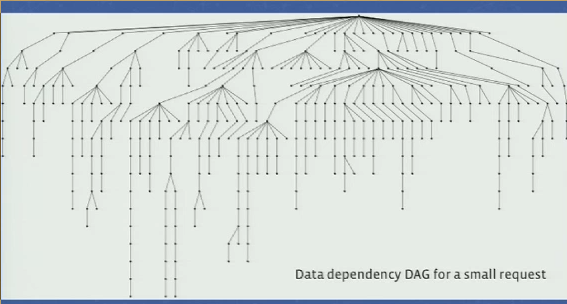
- data dependency graph for a small user request
Look-aside cache
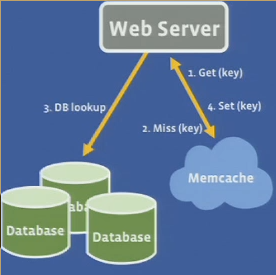
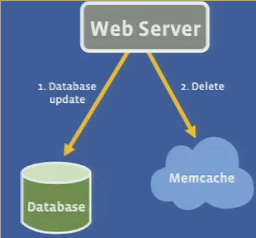
-
why deletes over set
- idempotent
- demand filled
-
webserver specifie which keys to invalidate after DB update
Invalid sets
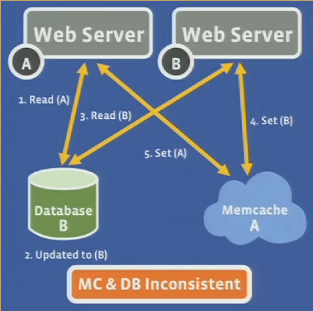
- attach lease-id with every miss
- lease-id invalidated on a delete
- cannot set if lease-id is invalidated
Q: who sets the lease-id Q: how do you invalidate someone else’s lease-id Q: how many do you order the lease-id
- CAS : is this like load-link/store conditional
- CAS is weaker because it will write if value read is the same as last read
- LL/SC will not write if there has been an update
- tagged state reference (add a tag to indicate how many times modified)
Thundering herds
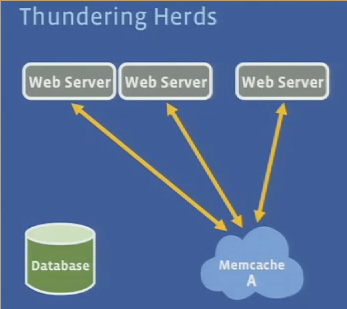
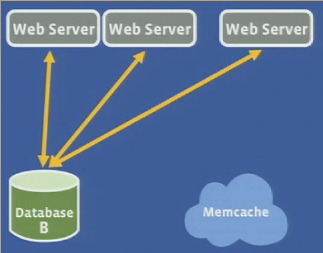
Q: how do you prevent thundering herds?
- Memcache informs WS that it will be updated soon by some other WS
- WS can then wait for the update or use stale value
All-to-all communication
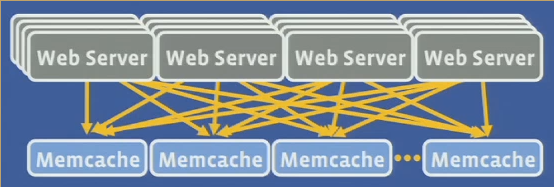
- Incast congestion
- amplification of data from memcached
- limit the number of outstanding requests
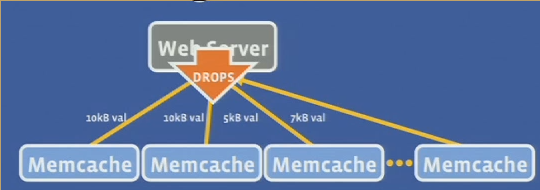
- Limits horizontal scalability
- multiple memcached clusters “front” one DB
- consistency
- over-replication
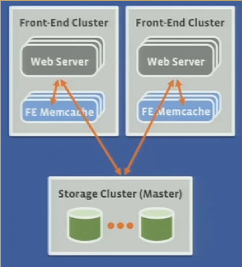
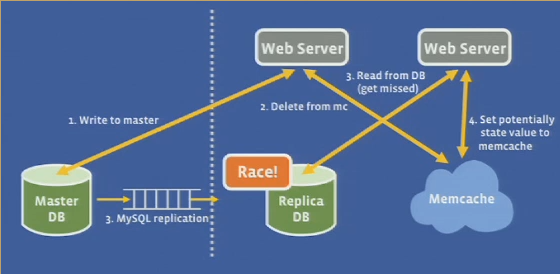
DB cache invalidation
- Cached data invalidated after DB updates
- Issue deletes from commit log
Q: MC still serving stale data? Why not invalidate pre-emptively?
- Too many packets a. intra-cluster BW > inter-cluster BW b. aggregation reduces packet rate by 18x c. easier configuration management, each layer just needs to know next d. each stage can buffer deletes in case of downstream components
Geo distributed clusters
Lessons
- push complexity to the client
- there are no server to server communication
- operation efficiency is as important
- routing pipeline
- slower
- configuration tight and local
- separate cache and persistance separate
Q&A
- bottle neck single memcache
- tail of memcache provision for the tail
- memcache flash
- have a fast in-memory
- fetch a lot of data
- small data problem - not a big data problem
- size of cache/average utilization
- different pools
- cache just store the hot heads
Questions:
3/2/-1 : web servers rely on a high degree of parallelism and over-subscription to achieve high throughput
-
coalescing connections to improve efficiency to reduce network
-
incast congestion
- sliding window talk about small window and large window
-
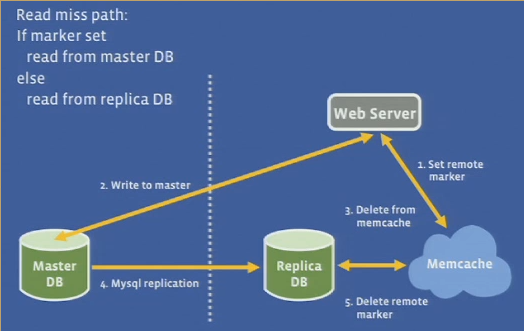
leases for state sets
- happens when a WS sets a stale value in mc
-
leases for thundering herds
- update on heavy read causes traffic to DB
-
lease
- mc gives a lease to a client
- 64-bit token bound to a key
- client provides the lease token when setting the value
- mc can verify and arbitrate concurrent writes
- verification can fail if mc has invalidated the lease token due to delete
- like load-link/store-conditional
-
thundering herds
- regulates the rate at which it return tokens
- return a token only once every 10s/key
- requests within 10s after giving out a token
- inform client to wait a short amount of time
- typically the client with the lease will have set the data within few milliseconds
-
stale values
- allow return of stale values while waiting for lease
-
mc pools
- what is its purpose
-
replicating within a pool
- application fetches many keys simultaneously
- entire data set fits in one or two mc servers
- request rate is high
- vs partitioning
- 100 keys and 500k qps
- each request asks for 100 keys
- overhead of getting 100 keys vs 1 key is about the same
- to scale to 1M qps
- add a second server and split the key space equally between the two
- each server will now have to handle 1M qps
- add a second replica
- each server will now each handle 500k qps
- add a second server and split the key space equally between the two
-
failures and gutter
- explain why there are cascading failures
- if get fails from normal mc, try to get from gutter, if not there get from DB, and populate it
- no invalidation in gutter, it expires by time
- rehashing keys among remaining mc servers, shunting hot load to another mc server can also cause cascading failure
-
why split front end clusters
- scaling with more WS and MC servers not good
- more incast
- region contains multiple front end clusters
- trade replication of data
- more independent failure domains
- tractable network configuration
- reduction of incast congestion
- region has multiple FE cluster and one store
-
invalidation
- storage cluster is responsible for invalidating cached data to keep frontend clusters consistent
- WS sends invalidations to its own cluster
- invalidations happen after commit
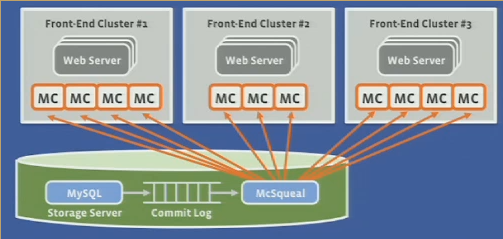
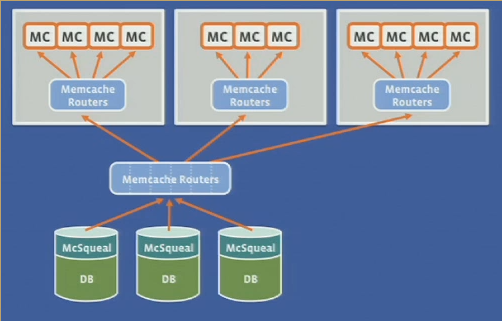
- mcsqueal is a daemon that inspect SQL statements and DB commits
- extracts any deletes and broadcasts to mc in every FE cluster
- batching of invalidation
- mcsqueal is a daemon that inspect SQL statements and DB commits
-
regional pools
- FE can share mc pools
- cross cluster incurs latency, 40% less BW intercluster
- replication trades more mc servers
- less inter-cluster BW
- lower latency
- better fault tolerance
- for some data it is more cost efficient to forgo replication and
have single copy per regional
- category B - infrequently access items -> put them in regional pools
- cold cluster warmup
- allow clients to get data from warm cluster
- inconsistencies
- cold makes an update
- cold get a read from warm -> stale -> becomes indefintely inconsistent
- memcached supports non-zero hold-off times that reject add operations for a specific hold-off times (2 seconds)
- FE can share mc pools