ARTICLES
Flink
By adam
What is it
- a distributed runtime
- uses pipelines for execution
- exactly-once state consistency
- lightweight checkpoint
- iterative processing
- windows semantics
- out-of-order processing
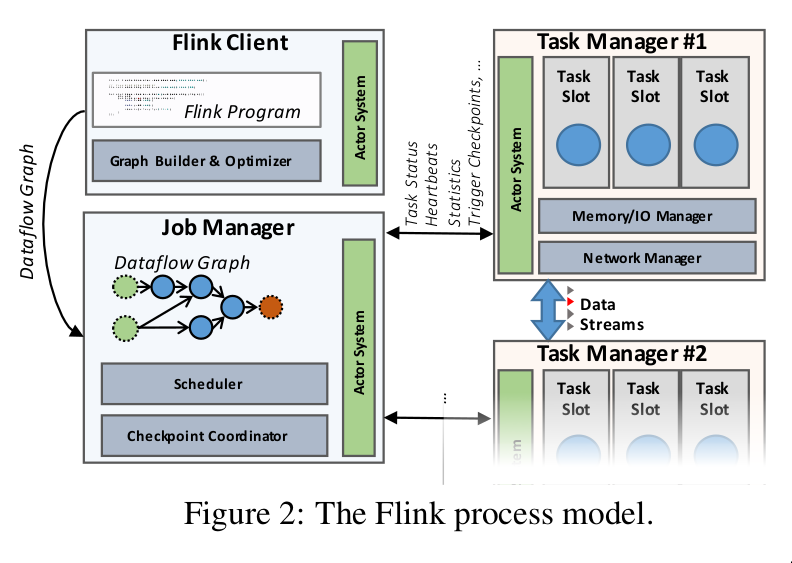
2 architecture
cluster
- client
- job manager
- task manager (1 or more)
client
- takes a program
- xforms to dataflow graph
- submits to job manager
- creates data schema and serializers
- cost-based query optmization
job manager
- coordinates distributed execution of dataflow
- tracks state and progress of each operator and stream
- schedules new operators
- coordinates checkpoints and recovery
- persists minimal set of data for checkpoint and recovery
task manager
- executes one or more operators
- report status to job manager
- maintain buffer pools to buffer or materialize streams
- maintain network connections to exchange of streams between operators
3.1 dataflow graphs
- stateful operators
- data streams
- data-parallel fashion
- operators -parallelized into one or more parallel instances (subtasks)
- stream split into one or more stream partitions
3.2 data exchange
Intermediate data streams
- core abstraction for data-exchange between operators
- represents a logical handle
Pipelined streams
- propagate back pressure from consumers to producers
- via intermediate buffer pools
- avoid materializatoin when possible
Blocking streams
- buffers all the producing operators data before making available for consumers
- used to isolate successive operators
- ex. sort-merge joins may cause distributed deadlock
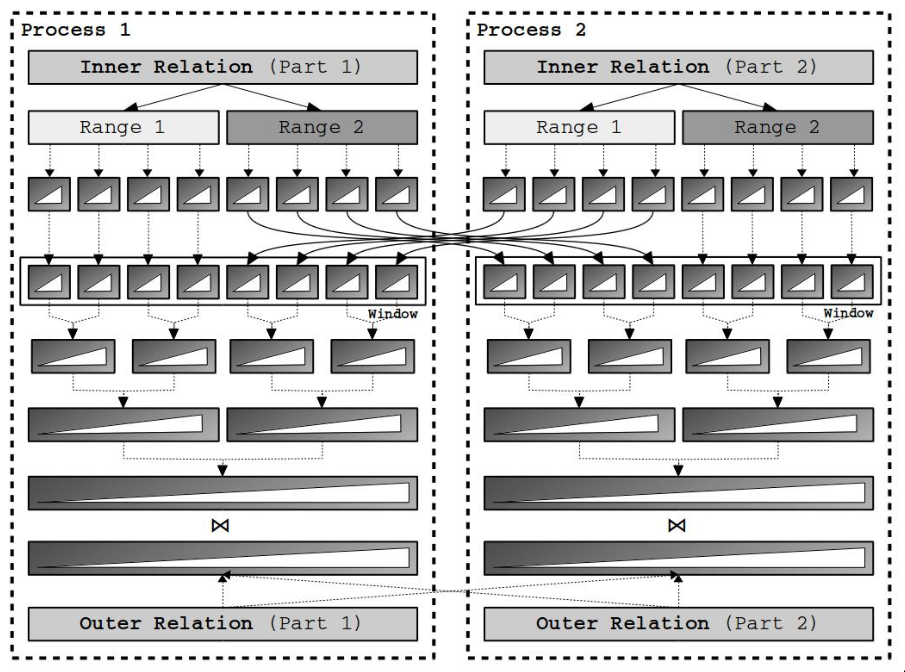
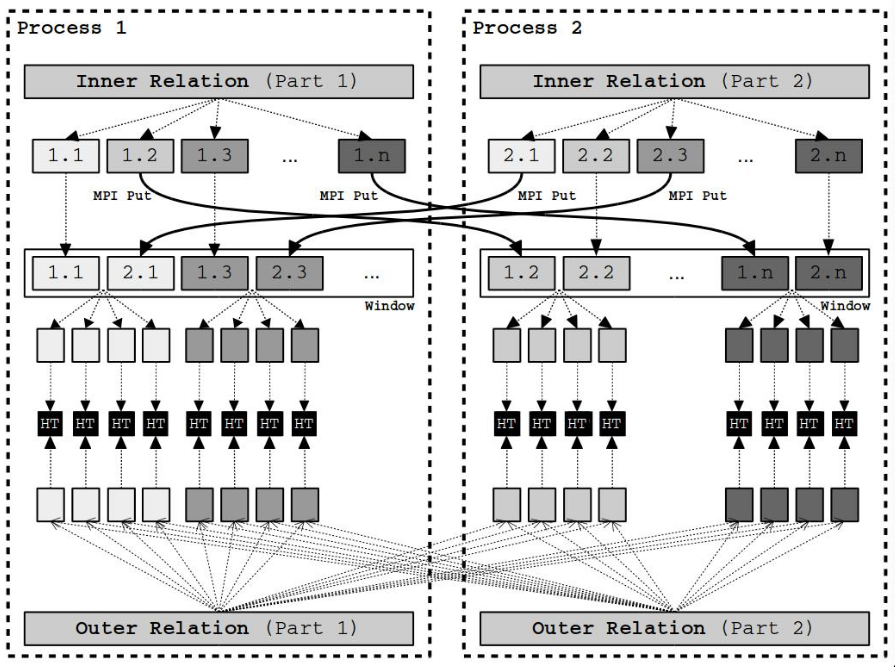
- ex. sort-merge joins may cause distributed deadlock
implementation
- exchange of buffers
- set high buffer size (1kB) for high throughput
- set low timeout (2 ms) for low latency
control
- checkpoint barriers
- watermark signals
- iteration barriers
- unary operators consule in FIFO order
- more than one stream merge in arrival order
- Flink does not provide ordering guarantees after repartitioning
- let the operators figure out how to deal with out of order
3.3 fault tolerance
- promises exactly once processing consistency
- uses checkpointing and partial re-execution
- data sources are persistent and replayable
- take consistent snapshot of all operators
- must refer to same logical time in the computation
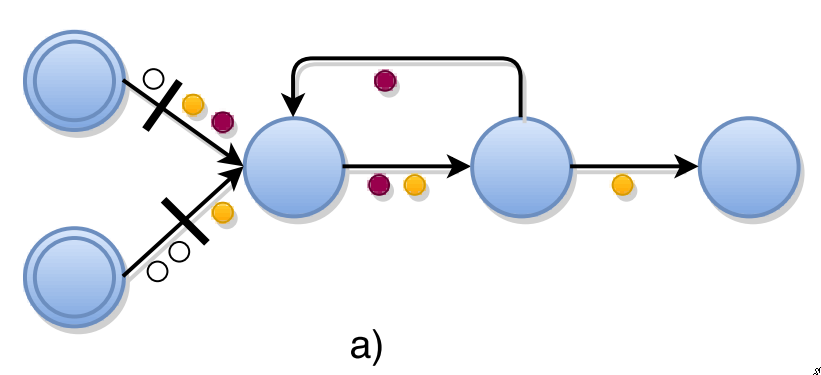
- Asynchronous Barrier Snapshotting
- operator receives barriers from upstream
- perform alignment
- make sure barriers from all inputs have been received
- operator writes its state to persistent storage
- after backup, forwards the barrier
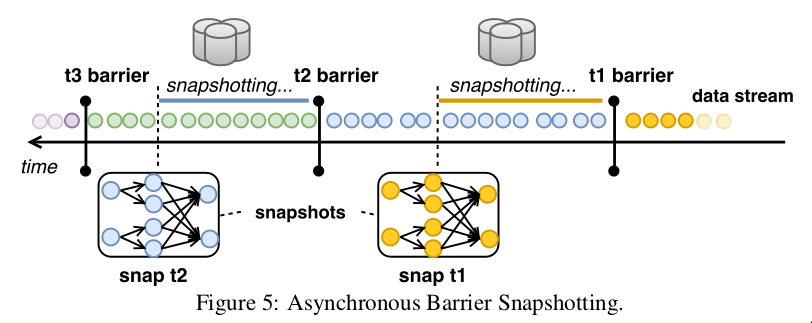
- Example: snapshot t2 contains all operator states that are the result of consuming all records before t2 barrier.
- don’t need to snapshot in-flight records
- restart from lastest barrier with a snapshot
- guarantees:
- exactly once state updates
- decoupled from control
- decoupled from how it is stored
Details
-
Paper: Lightweight Asynchronous Snapshots for Distributed Dataflows
-
Central coordinator periodically injects stage barriers
-
When source receives a barrier
-
takes snapshot of its current state
-
broadcasts the barrier to all its output
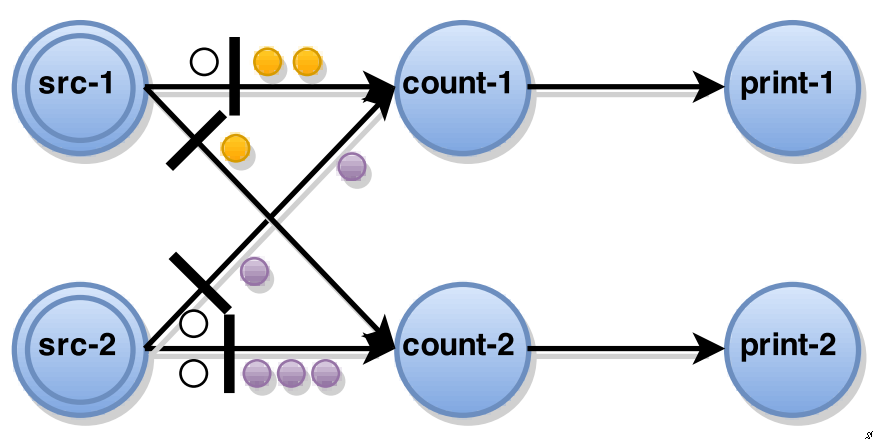
-
-
When a non-source task receives a barrier
-
blocks that input until it receives a barrier from all inputs
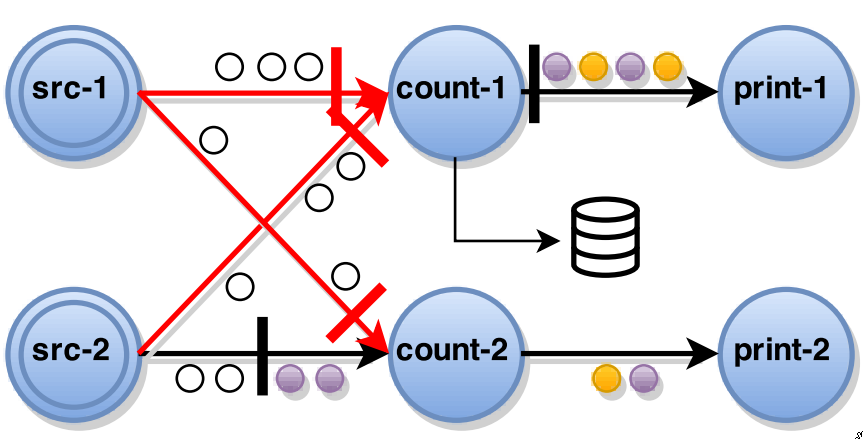
-
when all barriers have been received task takes snapshot of current state and broadcasts the barrier to its outputs
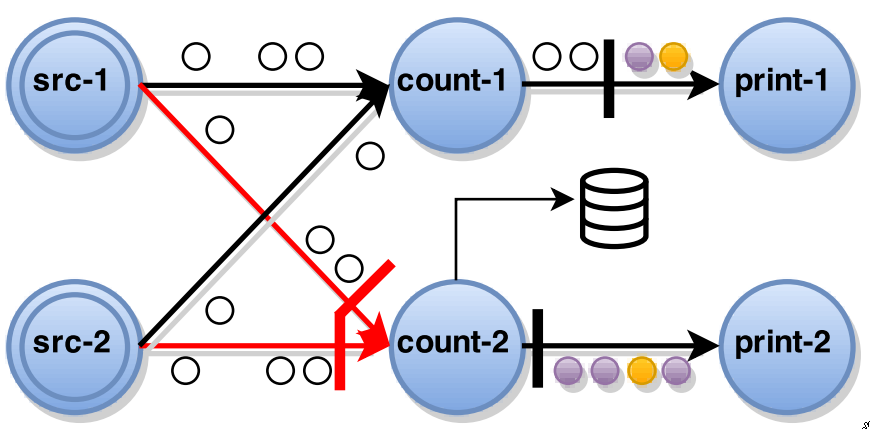
-
task unblocks its input channels to continue computation
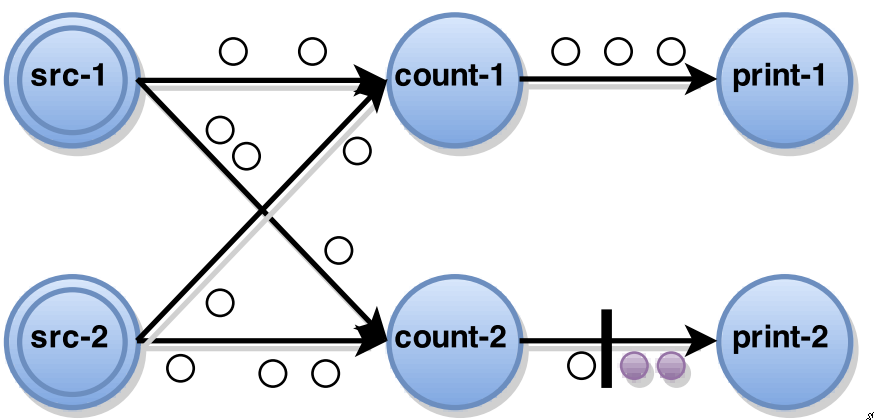
-
-
legend
-
The complete global snapshot \(G^* = (T^*, E^*)\) will contain only snapshots of the operator states, edge states don’t need to be saved
-
Algorithm for non-cyclic graphs

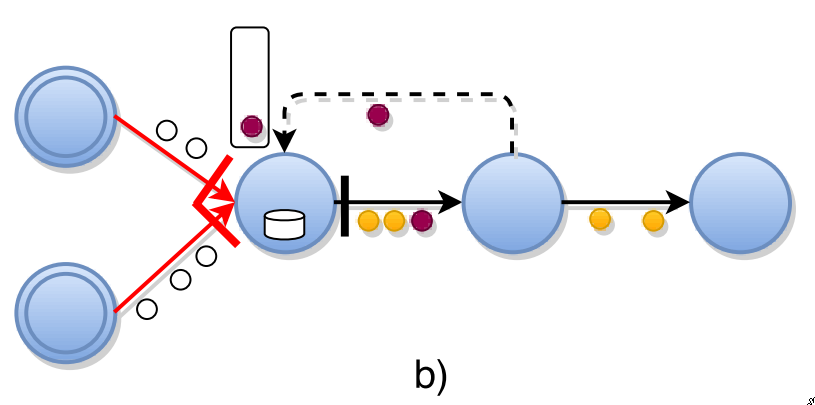
cyclic graphs
-
with cycles you will end up in a deadlock
- downstream tasks will be blocked because they have not received a barrier
-
records in transit in cycle would not be included in snapshot
-
first indentify:
- back-edges
- \(G(T,E\L)\) remove them, now you have a DAG
- backup records received from back-edges
- task \(t\) that has a back-edge: \(L_t \in I_t\)
- \(I_t\) creates a backup log of all records received from \(L_t\), when it forwards barriers until receiving the barrier back in \(L_t\)
-
Tasks with back-edge inputs create a local copy of their state once all the regular (\(e \notin L\)) channels delivered barriers.
-
Allows all pre-shot recods that are in transit with loops to be included in the current snapshot
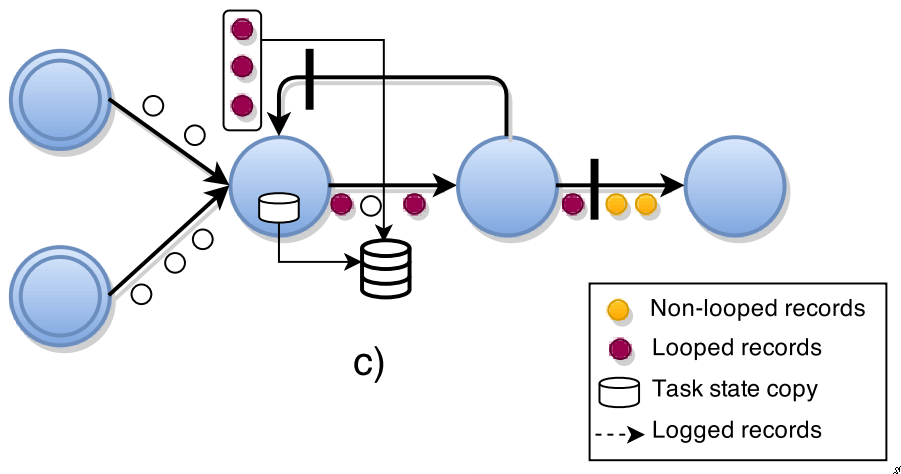
The final global snapshot will include the back-edge records in transit: \(G^* = (T^*, L^*)\).
-
Algorithm

3.4 iterative dataflows
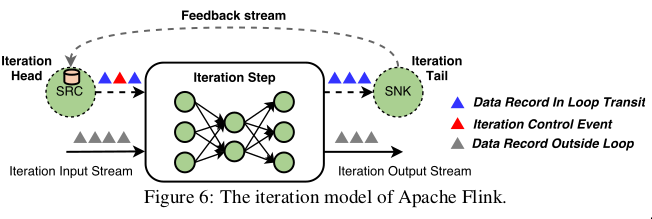
- implemented as iteration steps
- special operator that can contain an execution graph
- to maintain DAG
- introduce an iteration head and tail tasks
- implicitly connected with feedback edges
- tasks establish active feedback channel
- provide coordination for processing data records
- introduce an iteration head and tail tasks
time
- event time
- process time
- low watermarks mark gloval progress measure
- time t such that all events lower than t have already entered operators
- allow processing in correct event order and serialize operations
- originate from the sources
- propagates to other operators
- map and filter just forward the watermarks
- complex operators compute events triggered by a watermark, then fwd
- if more than one input, only fwd the min of incoming watermarks
- processing time used for lower latency
- ingestion time: somewhere in between event time and processing time
stateful stream
- windows are stateful operators
- fill memory buckets
- operator annotation used to statically register explicit local variables
- k-v states declared with an operator
- registered state is durable with exactly-one update
windows
- definition
- assigner: assign record to logical window
- a record can be assigned to multiple windows
- as in sliding window
- a record can be assigned to multiple windows
- trigger: defines when the operation will be performed
- evictor: determines what to keep
- assigner: assign record to logical window
- types
- periodic time
- count windows
- punctuation
- landmark
- session
- delta
Example
stream
.window(SlidingTimeWindows.of(Time.of(6, SECONDS), Time.of(2, SECONDS))
.trigger(EventTimeTrigger.create())
- assigner: range 6 seconds, every 2 seconds
- trigger: results computed once the watermark passes the end of the window
stream
.window(GlobalWindow.create())
.trigger(Count.of(1000))
.evict(Count.of(100))
- assigner: all events go to a single logical group
- trigger: every 1000 events
- evictor: keep only the last 100 elements
async stream iteration
feedback streams are treated as operator state
Batch analytics
- query optimiztion
- memory management
- batch iterations
Query optimization
- optimizer doesn’t know about UDF’s
- cardinality: uses hints from the programmer
- plan uses costs like network disk I/O and CPU
- strategies
- repartitioning
- broadcast data transfer
- sort based grouping
- sort based and hash based join
Memory management
- manages data into memory segments
- sorting and joining work on binary
- off-heap and binary
- reduce gb
- cache efficient
Iteration control
// set up execution environment
env = ExecutionEnvironment.getExecutionEnvironment();
// get input data:
// read the points and centroids from the provided paths
// or fall back to default data
points = getPointDataSet(params, env);
centroids = getCentroidDataSet(params, env);
// set number of bulk iterations for KMeans algorithm
loop = centroids.iterate(params.getInt("iterations", 10));
newCentroids = points
// compute closest centroid for each point
.map(new SelectNearestCenter()).withBroadcastSet(loop, "centroids")
// count and sum point coordinates for each centroid
.map(new CountAppender())
.groupBy(0).reduce(new CentroidAccumulator())
// compute new centroids from point counts and coordinate sums
.map(new CentroidAverager());
// feed new centroids back into next iteration
finalCentroids = loop.closeWith(newCentroids);
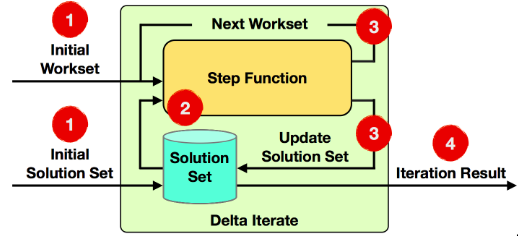
delta iterate
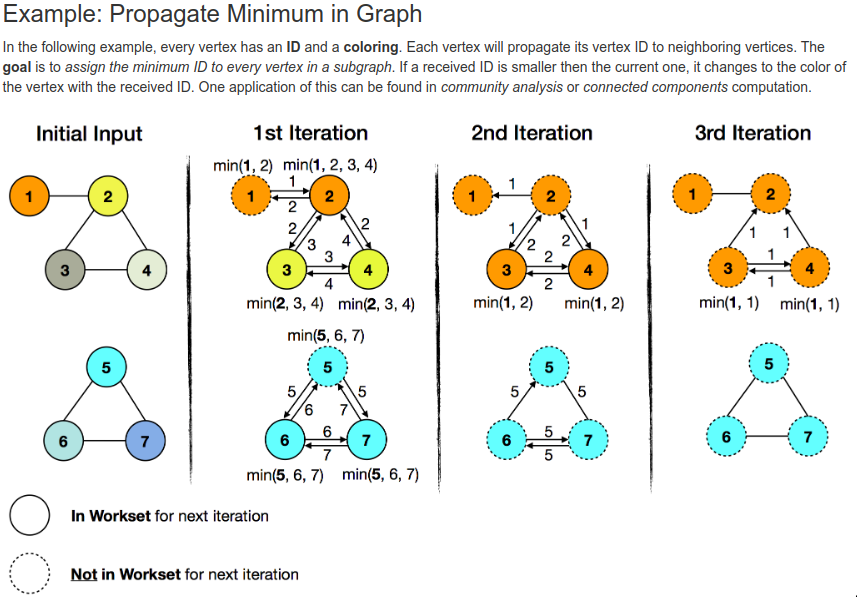
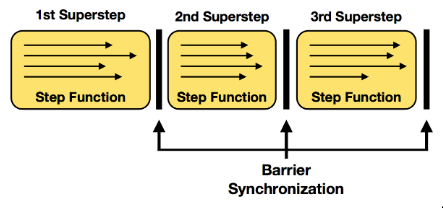
Bulk synchronous parallel
- concurrent computation
- communication
- barrier synchronization

- cost of BSP from wikipedia
\[\max_i w_i + \max_i h_ig + l\]
- \(w_i\) is the computation cost
- \(h_i\) the number of messages
- \(g\) cost per message
- \(l\) barrier synchronization cost
- this is for one superstep
superstep synchronization
Stale synchronous parallel
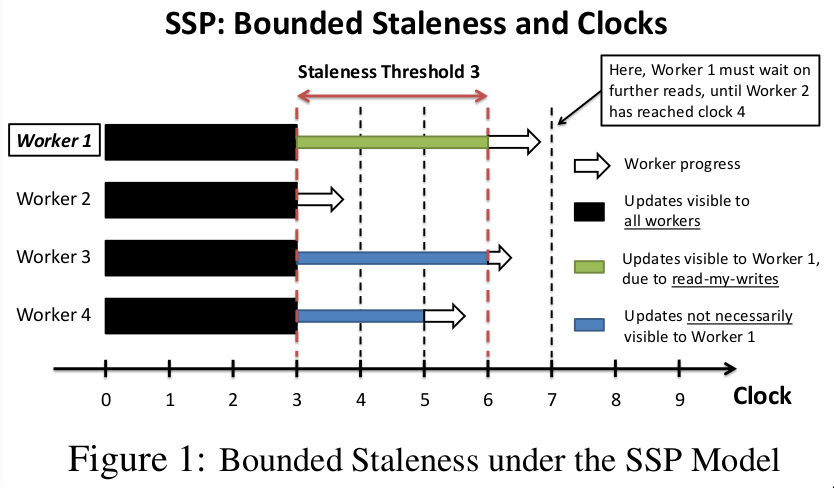
- workers at clock \(c\) can see updates at \([0,c-s-1]\)
- here \(c\) counts the iterations in some algorithm, not wall clock time
- \(s\) is a bound for staleness, guarantee that all workers at at most \(s\) cycles away from each other
- workers can always see their own updates \([0,c-1]\)
- workers may see some updates from other workers \([c-s,c+s-1]\)