ARTICLES
Spanner
By adam
Key to paper
TrueTime exposes clock uncertainty, if the uncertainty is large, Spanner slows down to wait out the uncertainty. TS reflect serialization order, external consistency, or linearizability.
Spanner zones
Zone
- zonemaster assigns data to spanservers (1000)
- location proxies used by clients to locate spanservers
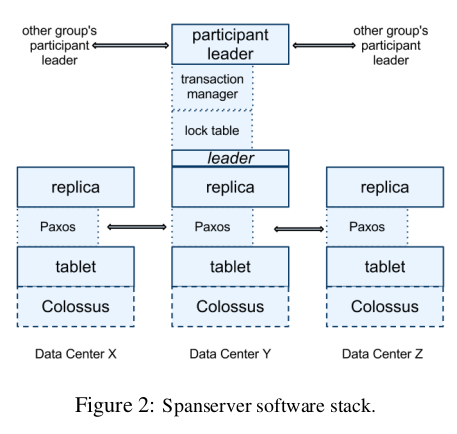
Spanserver
- responsible for 1000 tablets
Tablet
- (key: string, timestamp: int64) -> string
- more like multiversion kv store
- state store in a set of B-tree-like files and a write ahead log
- in DFS called colossus
- one Paxos state machine per tablet
Paxos
- long time leader leases (10 sec)
- implements a consistently replicated bag of mappings
- writes initiates paxos protocol at leader
- reads access state directly from any replica
- set of replicas called Paxos group
Logs:
- every ‘Paxos write’ goes to tablet log and to Paxos logic
Replica leader
- every leader replica implements a lock table
- contains the state for 2-phase locking
- maps ranges of keys to lock states
- leaders are long lived to maintain this lock table
- performs poorly under optimistic concurrency control
- replicas in paxos group called participant slaves
- implements a transaction manager
- implements a participant leader
- used between other paxos groups for 2-phase commit
Participant/Coordinator
- one participant leader (leader to a paxos group) is chosen as coordinator leader, other replica leader called coordinator slaves
- state of transaction manager store in underlying paxos group
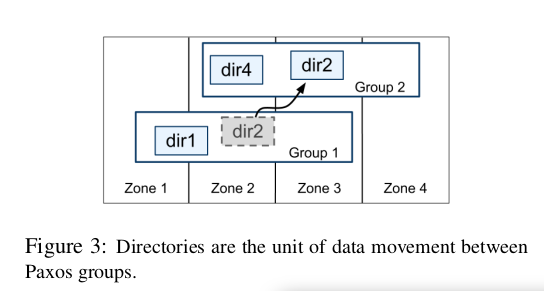
Directory and placement
directory
- set of contiguous keys with common prefix
- unit of data placement -> same replica config
- unit of data movement between paxos groups
paxos group/tablet
- contains multiple directories
- not necessarily lex. cont. partition of row space
- collocate directories that are freq. accessed together
movement/movedir
- used to add and remove replicas to p.groups
- not implemented as a single transaction
- void blocking ongoing reads and writes
- moves data in the background
- small remaining amount uses a transaction to atom. move and update the metadata for the two paxos groups
geographical replication
- directory smallest unit for rep. config
- Options:
- North America (one dimension)
- replicated 5 ways with 1 witness (second dimension)
- application tags data with these controls
- store user A in 3 replicas in Europe
- store user B in 5 replicas in NA
fragments
- directories are sharded into multiple fragments
- may be served from different Paxos groups
- movedir moves fragments
Data model
- megastore
- easier to use, trumps performance
- supports sync replication across dc’s
- gmail, picasa, calendar, market, appengine
- dremel
- interactive data analysis tools
- bigtable
- no cross-row transactions
applications
- directory-bucketed kv mappings
- db can contain number of tables
data model
- row have names
- table must have ordered set of one or more primary key cols
- primary keys form the name for a row
- table defines mapping from primary key cols to non-primary-key cols
hierarchy
- INTERVEAVE IN: create a sub-directory
- directory table: table at top of hierarchy
- directory: row K in directory table + all rows in descendant tables with key K
- ON DELETE CASCADE: remove row K in directory table + propagate

- Albums are interleaved with the users
TrueTime
TT.now() : returns TTinterval: [earliest, latest]
-
timemaster per datacenter
- have GPS receivers
- all timemasters’ are compared against each other
-
armageddon master have atomic clocks
- between syncs, armageddon masters ad a slowly inc time uncertainty
-
timeslave daemon per machine
- poll from masters
- implement Marzullo’s algo to detect and reject liars
- sync local clock to non-liars
- between syncs, daemon ad a slowly inc time uncertainty
- polls every 30s
- drift of 200us/s
- 6 ms drift per polling + 1 ms communication delay
Concurrency control
- TrueTime allows
- externally consistent transactions
- lock-free read-only transactions
- non-blocking reads in the past
- audit read at TS t
Note: distinguish between Paxos writes and Spanner writes
- paxos writes for 2-phase commits
TS management
- supports
- RW transactions
- read only transactions
- snapshot reads
- standalone writes -> rw transactions
- non-snapshot reads as read only
- read-only trans
- no writes
- execute at a system-chosen TS without locking
- incoming writes not blocked
- can go to any replica that is sufficiently up-to-date
- snapshot read
- read in the past without locking
paxos leader lease
- leaders live 10 seconds
- leader requests timed lease votes, if it gets a quorum it knows it has a lease
- replica extends its lease vote on a succ writes
- lease interval starts when it discovers it has a quorum
- ends when it no longer has a quorum (because of expiration)
- paxos leader lease interval is disjoint from other’s
- abdication is permissible must wait TT.after(smax)
- trans read and writes use two-phase locking
- TS when all locks acquired, before any release
- Spanner assigns TS that Paxos assigns to Paxos write (commit)
- DEPENDS on the monotonicity invariant
- in each group, Spanner assigns TS to Paxos writes in mon. inc. order, even across leaders
- simple in single leader
- enforced across leaders by disjointness invariant
- leader must only assign TS within interval of its leader lease
- when TS s is assigned, smax is advanced to s to preserve disjointness
externally consistency invariant
- if start of T2 is after commit of T1, T2’s commit time > T1’s commit time
- define events for trans Ti: ei.start ei.commit si (commit time)
- t(e1.commit) < t(e2.start) => s1 < s2

-
Define arrival event of a commit request at coordinator for the write of a transaction Ti to be ei(server)
-
Start
si > TT.now().latest @ ei(server)
-
Commit wait
- coordinator leader ensure that clients cannot see any data committed by Ti until TT.after(si)
si < TT.now().earliest @ ei(commit)
tsafe
-
when is it safer to read?
-
each replica keeps a tsafe, which is the max TS at which a replica is up-to-date, i.e. read are safe if TS(read) <= tsafe
-
define
tsafe = min(tpaxos(safe), ttm(safe))
-
tpaxos(safe) = TS of the highest-applied paxos write
-
ttm(safe)
-
\(\infty\) if there are zero prepared but not committed transactions
-
coordinator ensures that
si >= si,g(prepare)
i.e. transaction’s commit TS is greater that all participants si,g(prepare) amont all participant groups g
-
ttm(safe) = mini(si,g(prepare)) -1 over all transactions prepared at g
-
read-only transactions
RO transactions 2 phases:
- assign TS sread
- execute read from snapshot at sread
sread > TT.now().latest @ ei.start
- preserves external consistency
- may require block if tsafe has not advanced sufficiently
- sread may also advance smax to preserve disjointness
- to reduce blocking, assign the oldest TS that preserves external consistency
TrueTime details
Microbenchmarks
- snapshot read execute on any up-to-date replica
- linear increase with # replicas
- single read read-only execute at leaders because of TS
- linear increase because # of effective spanservers increases
- write throughput
- some increase but now more work to write to replicas
TrueTime
worst uncertainty by bad CPUs
F1
- 10 TB data
- difficulties in sharing MySQL
- assigned each customer and related data to a fixed shard
- allowed indexes and complex query processing on a per-customer basis
- business logic has to be aware of sharding
- resharding takes a longtime
- Spanner
- don’t have to manually reshard
- provides synchronous replication and failover
- transactional semantics
- consistent global indexes
- application writes through Spanner
- timestamps - F1 can maintain in-mem data struct computed from DB state
- logical history log of all changes
- snapshots for init and reads inc changes
- most directories in one fragment
- write latency pretty fat tail due to lock conflicts
- read latency larger SD due to paxos leaders spread across two data centers
Related work
- integrating multiple layers:
- integrating concurrency control with replication reduces the commit cost
- layering transactions on top of replication
- reduce locking overheads
- master slave replication over large area
- derivation of clock uncertainty
Future work
- Moving data between datacenters automatically
- Move client-application processes between datacenters
Conclusions
Linchpin is TrueTime